 使用tesseract进行验证码识别
使用tesseract进行验证码识别
项目目的
在使用python进行web爬虫过程中,验证码是一个无法绕过的问题,一些大型网站会采用比较高级的验证方式,如图片点选,滑动图片等等。
今天进行的是较低一级的验证码图片的识别,即图片上的字母和数值上有横线如何进行识别。如下图,当然现今有很多站点提供api可供大家进行识别,我们要做的是如何在本地搭建一套这样的验证码识别系统,供自己使用

对于像12306网站这种网站上的图片点验证码识别比较麻烦,应该使用的是神经网络识别系统,之后有时间会实践一下,更新一个专门关于神经网络识别验证码的博客。
软件环境
- 系统版本centos7.4.1708
- python版本3.6.5
- tesseract版本4.1.0
- leptonica版本1.78.0(tesseract包的安装依赖)
- PIL库图片过滤
- tesseract数据训练验证码
安装及部署
一. 安装并编译leptonica
1.安装依赖包
#yum install gcc autoconf automake libtool libjpeg-devel libpng-devel libtiff-devel zlib-devel -y
2.下载leptonica-1.78.0并编译、加载环境变量
#wget http://www.leptonica.org/source/leptonica-1.78.0.tar.gz
#tar xzvf leptonica-1.78.0.tar.gz
#cd leptonica-1.78.0
3.编译并安装
#./autogen.sh
#./configure
#make
#make install
4.添加环境变量
#vim /etc/profile
5.最后添加如下内容
#export LD_LIBRARY_PATH=$LD_LIBRARY_PAYT:/usr/local/lib
#export LIBLEPT_HEADERSDIR=/usr/local/include
#export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
6.执行如下命令使之立即生效
#source /etc/profile
二.下载并安装tesseract4.1.0
1.安装tesseract
#wget https://github.com/tesseract-ocr/tesseract/archive/4.1.0.tar.gz
#tar xzvf tesseract-4.1.0.tar.gz
#cd tesseract-4.1.0
2.编译并安装
#./autogen.sh
#./configure
#make
#make install
3.查看tesseract版本
#tesseract --version
4.1.0
三.training的编译安装
1.安装依赖库
#yum install libicu-devel pango-devel cairo-devel -y
2.下载并安装libarchive
#wget http://www.libarchive.org/downloads/libarchive-3.3.3.tar.gz
#tar xzvf libarchive-3.3.3.tar.gz
#cd libarchive-3.3.3
###编译并安装
#./configure
#make
#make install
3.下载安装icu52版本,不安装这个软件包training会包icu版本较低错误
#wget http://download.icu-project.org/files/icu4c/52.1/icu4c-52_1-src.tgz
#tar -xvzf icu4c-52_1-src.tgz
#cd icu/source/
###编译并安装
#./runConfigureICU Linux --with-library-bits=64
#make -j 5
#make install
4.创建软连接
#ln -s /usr/local/lib/libicui18n.so.52 /usr/lib64/libicui18n.so.52
#ln -s /usr/local/lib/libicuio.so.52 /usr/lib64/libicuio.so.52
#ln -s /usr/local/lib/libicuuc.so.52 /usr/lib64/libicuuc.so.52
#ln -s /usr/local/lib/libicudata.so.52 /usr/lib64/libicudata.so.5
5.编译并安装traning
#./configure
#make training
#make training-install
6.有如下提示training安装成功
lstmtraining --version
4.1.0
四. 下载用于图片训练的验证码
1.去网上下载用于验证码训练的图片1000+张
我使用的验证码sample:https://www.kaggle.com/fournierp/captcha-version-2-images 有兴趣可以自己制作验证码:https://pypi.org/project/captcha/
2.将1000+张验证码图片分成二部分,一部分用于tesseract数据训练,一部分用于测试训练后的识别准确率
这里将500+张待训练验证码放在/root/samples_training/下,将500+张待验证验证码放在/root/samples_test/下。
待训练原始验证码存储路径:/root/samples_training/
待训练降噪后验证码存储路径:/root/samples_training_convert_image/
待训练过滤后验证码存储路径:/root/samples_training_after_filter/
待验证原始验证码存储路径:/root/samples_test/
待验证降噪后验证码存储路径:/root/samples_test_convert_image/
待验证过滤后验证码存储路径:/root/samples_test_after_filter/
执行过程中convert_all_training_image.py、convert_all_test_image.py、1.bash、result.py所在路径:/root/zhai/ocr/1-17/
五. 使用PIL库进行图片过滤
#python convert_all_training_image.py
代码如下:下载地址下载
from PIL import Image,ImageFilter
import os
path="/root/samples_training" #设置sample图片路径
'''PIX函数作用是对图片进行降噪处理
通过getpixel获取每个像素所对应的二值的数值,然后根据规则进行降噪处理
降噪规则有很多种,包括4格,8格,大于5格等等,根据实际的情况进行选择'''
def pIx(data,iteration=1):
w,h=data.size
for x in range(1,w-1):
if x > 1 and x != w-2:
left = x - 1
leftleft= x - 2
right = x + 1
rightright = x + 2
for y in range(1,h-1):
up = y - 1
upup = y - 2
down = y + 1
downdown = y + 2
if x <= 2 or x >= (w - 2):
data.putpixel((x,y),1)
elif y <= 2 or y >= (h - 2):
data.putpixel((x,y),1)
elif data.getpixel((x,y)) == 0:
if y > 1 and y != h-1:
up_color = data.getpixel((x,up))
down_color = data.getpixel((x,down))
downdown_color = data.getpixel((x,downdown))
left_color = data.getpixel((left,y))
left_down_color = data.getpixel((left,down))
right_color = data.getpixel((right,y))
right_up_color = data.getpixel((right,up))
right_down_color = data.getpixel((right,down))
if (down_color == 0 and downdown_color == 1) or (left_color == 1 and right_color == 1 and up_color == 1 and down_color == 1) or (up_color == 1 and down_color == 1):
data.putpixel((x,y),1)
else:
pass
data.save(itcp+filename_prefix+'_strip_noise.png')
if iteration > 1:
iteration=iteration-1
pIx(data,iteration=iteration)
for filename in os.listdir(path):
image_training_path=path
image_training_convert_path='/root/samples_training_convert_image/'
itp=image_training_path#简化一下变量名
itcp=image_training_convert_path
img=Image.open(itp+filename)
Img=img.convert('L') #转换成灰度图
filename_prefix=filename.split(".")[0]
Img.save(itcp+filename_prefix+'_gray.png')
######下面是二值化图片过程###########################
threshold=143 #阈值设置成143,根据图片的情况进行设置
table=[]
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
photo=Img.point(table,'1')
photo.save(itcp+filename_prefix+'_blackwhite.png')
pIx(photo,iteration=2) #因为图片上的横线大概是两像素宽度,所以这里迭代2次
然后执行下面代码
#chmod 777 1.bash
#sh 1.bash
代码如下:下载地址下载
#!/bin/bash
#将所有png图片拷贝到新目录下,以防误删除,因为图片过滤500张大概需要3个小时
cp /root/samples_training_convert_image/* /root/samples_training_after_filter/
cd /root/samples_training_after_filter
#去除掉中转图片
shopt -s extglob
rm -rf !(*strip*)
#将图片以结果名称重命名 如:e2d66_strip_noise.png---->e2d66.png
for i in `ls`
do
rename "_strip_noise" "" *
done
#将png格式图片转化为tif
for i in `ls`
do
k=${i%.*}
convertformat $i $k.tif
done
#将png图片删除
rm -rf *.png
python代码主要是下面三个功能
(1)将图片转换成灰度图
(2)二值化处理
(3)降噪
bash脚本主要是下面两个功能
(4)png图片转换成tif图片
(5)只保留名称包含strip的图片,并将图片重命名为与真实验证码名称相同的图片
六. 对数据进行训练
这里使用jTessBoxEditor是在win7上进行的,因此合并后的tif文件,和修改后的box文件都需要上传到centos7服务器上
1.tif文件合并
用jTessBoxEditor工具,将样本文件合并成.tif文件。
我这里引用的别人教程中的图片,因为我写这篇博客用的家里的macbook,训练环境用的公司的win7系统,现在又正好放假,忘记截图保存了,但过程是一样的。
(1)将box文件和tif文件放在同一目录下
(2)Tools -> Merge TIFF,选择文件类型为all the images,选中所有图片 -> 命名为***.tif 合并为.tif文件
因为这里用的是别的博客上的图片,和我实际中命名的图片有冲突,我的环境中图片合并后的名字为engnum.zhai.exp0.tif,将合并后的tif文件上传到centos服务器上
2.生成box文件
#tesseract engnum.zhai.exp0.tif engnum.zhai.exp0 -l eng lstmbox
上一步执行完后会生成一个叫做engnum.zhai.exp0.box的文件,将这个文件和engnum.zhai.exp0.tif文件拷后到win7环境下
3.box文件调整
使用jTessBoxEditor对box文件进行调整,将识别出错的字符进行更改,这里需要注意的是因为用到了lstm,lstm是识别一行字符,而不是单个字符。即使用jTessBoxEditor打开文件后一行数据为一个框。这里用的是别人的图片实际调整按照一行一调整进行,保存的文件名不变
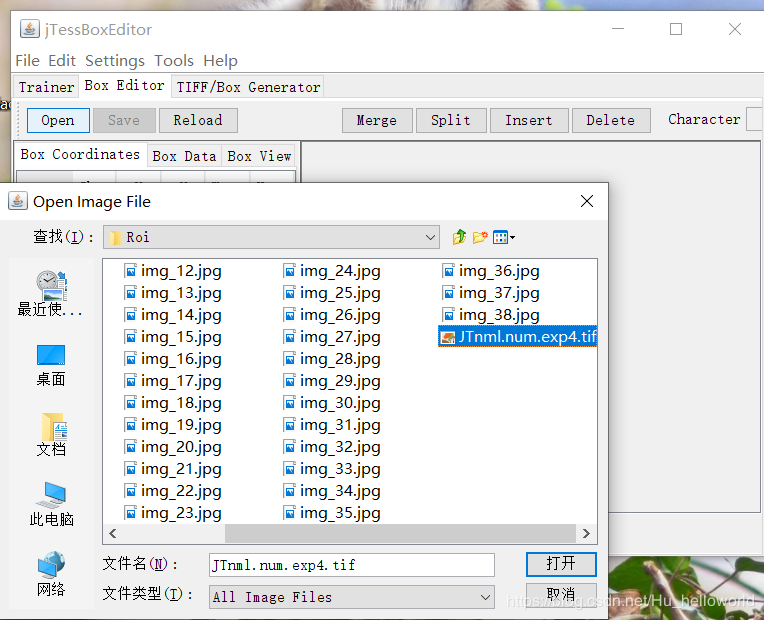
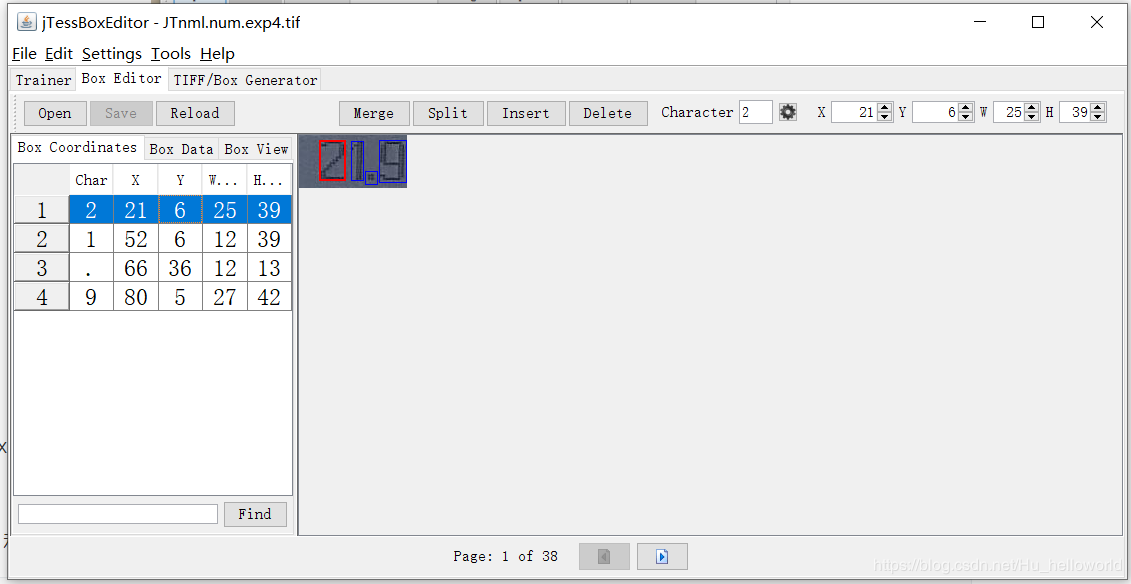
将调整后的box文件拷贝到centos服务器上
4.数据训练
(1)得到.lstmf文件,为之后的数据训练做准备
#tesseract engnum.zhai.exp0.tif engnum.zhai.exp0 -l eng --psm 6 lstm.train
(2)提取.lstm文件
从 https://github.com/tesseract-ocr/tessdata_best 链接中下载eng.traineddata文件
将上一步下载的eng.traineddata文件拷贝到服务器上,然后运行下面命令
#combine_tessdata -e eng.traineddata eng.lstm
运行上述代码,会从.traineddata文件中提取出eng.lstm 文件,将该文件放在/root/zhai/ocr/1-17/下
(3)创建包含 (1)步生成的训练文件路径的txt文件
#vim engnum.training_files.txt
代码如下
/root/zhai/ocr/1-17/engnum.zhai.exp0.lstmf
(4)生成数据训练checkpoint
#time lstmtraining --model_output="./output/" --continue_from="./eng.lstm" --train_listfile="./engnum.training_files.txt" --traineddata="./eng.traineddata" --debug_interval -1 --target_error_rate 0.01
–model_output:训练数据生成目录
–continue_from:(2)中提取出来的文件
–train_listfile:(3) 步内容
–traineddata:(2)下载内容
–-debug_interval 设置为-1时,命令运行后会显示一些结果参数
–target_error_rate 设置为0.01 为了准确率,将数值设置的小一些
(5)生成最终的数据训练集合
通过以下命令生成engnum.traineddata训练数据
#lstmtraining --stop_training --continue_from="/root/zhai/ocr/1-17/output/_checkpoint" --traineddata="/root/zhai/ocr/1-17/eng.traineddata" --model_output="/root/zhai/ocr/1-17/output/engnum.traineddata"
(6)将训练的数据放到指定位置
#cp /root/zhai/ocr/1-17/output/engnum.traineddata /usr/local/share/tessdata/
六. 验证码识别验证
1.将convert_all_training_image.py中的
image_training_convert_path='/root/samples_training_convert_image/'
替换成
image_training_convert_path='/root/samples_test_convert_image/'
2.将1.bash中的
cp /root/samples_training_convert_image/* /root/samples_training_after_filter/
cd /root/samples_training_after_filter
替换成
cp /root/samples_test_convert_image/* /root/samples_test_after_filter/
cd /root/samples_test_after_filter
3.重复之前五步骤中动作 即
python convert_all_training_image.py
sh 1.bash
4.进行验证码识别
验证码识别主要是使用tesseract命令,通过在result.py中调用subprocess.getoutput()和os.system()来执行命令。
python result.py
代码内容如下:下载地址下载
import os
import subprocess
path="/root/samples_test_after_filter" #过滤后待识别的图片验证码
sum=0
for filename in os.listdir(path):
sumnumber=len(os.listdir(path)) #待识别的文件总数
fileindexname=filename.split(".")[0] #取文件名.前面的部分
absolutefilename=path+'/'+filename #取绝对路径文件名
outputfilename=os.getcwd()+'/'+'file' #tesseract识别后生成的文件名
readoutputfile=os.getcwd()+'/'+'file.txt'#读取tesseract生成的文件名
command1="tesseract %s %s -l engnum" %(absolutefilename,outputfilename) #执>行tesseract识别图片验证码命令参数保存在command1中
command2="cat %s" %readoutputfile #将识别出的结果保存在command2变量中
os.system(command1) #将识别结果保存到file.txt中
value=subprocess.getoutput(command2) #取出识别结果赋值给value变量
value_strip_blank=value.lower().strip().replace(' ','') #字母变小写后再去掉>识别过程中存在的空格
if fileindexname == value_strip_blank:
sum=sum+1
print("当前图片识别结果是:%s" % value_strip_blank)
print("图片应当别识别为:%s" % fileindexname)
print("识别率为:{:.2%}".format(sum/int(sumnumber)))
识别率如下图所示:
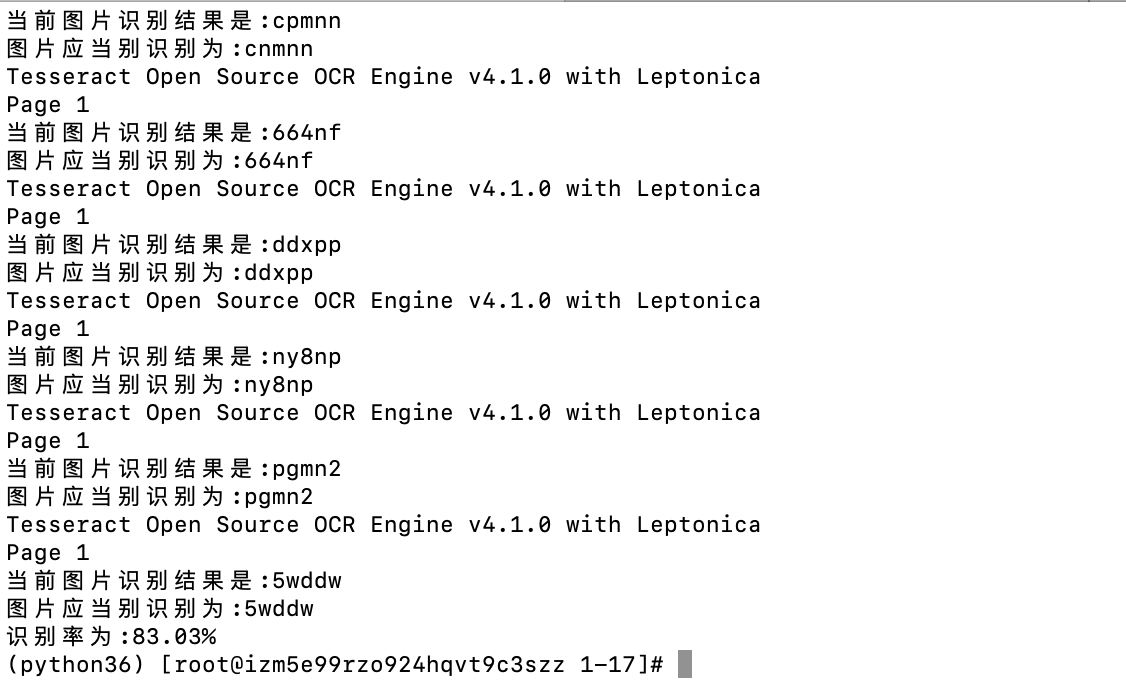
可以看出识别率约为83.03%,也就是10个图片能识别出8个左右,这样的识别效果我还算满意,当然想要更精确就要提供更多的训练素材
七. 总结
使用tesseract识别验证码的核心处理过程如下
1.将各种需要的软件及相关依赖安装好
2.使用PIL库对待训练的图片进行灰度、二值、降噪等处理
3.对待训练的图片进行合成、转换box文件
4.对box文件进行改错微调
5.使用lstmtraining进行数据训练
6.使用tesseract进行验证码识别
使用tesseract识别验证码,是有局限性的,而且干扰条件越多,过滤效果越不好,识别率越低,并且无法通过手工处理得到完美的模型,只能是尽量处理干扰条件,尽量完美。
之后根据需求会考虑用神经网络识别技术做验证码识别,到时候也会即时更新blog。
声明:本博客的原创文章,都是本人平时学习所做的笔记,转载请标注出处,谢谢合作。