 python中requests请求返回对象中content和text编码问题分析
python中requests请求返回对象中content和text编码问题分析
今天翻看资料的时候遇到了requests请求返回对象中content和text属性值调用后出现的编码的问题,有点不太理解这两个有什么区别,故通过上网找资料和自己实验,弄清楚了这两个属性值的返回值的区别
先上一段代码
# pip install requests
# req_test.py
import requests
res = requests.get("https://www.baidu.com")
print(res.content)
print(res.text)
通过返回结果分析如下
一. res.content返回的是bytes型数据,即二进制数据
res.content反馈结果,可以看到会传\x开头的一堆东西,\x后面跟的字母和数值代表的是它是16进制数,每4位二进制数可以构成1位16进制数(如4位1111对应16进制的F) 一个\x后跟着2个16进制数,所以一个”\xe5”这种代表8位二进制数即一个字节,即8bit,通过最前面的b’ 可以看到返回的结果是以字节形式保存的,也验证了这一消息.
并且通过观察可以判断之前使用的应该是UTF-8编码方式,因为UTF-8编码中文,是3个字节为一个字符
 可以通过在线解码工具查看一下转换结果
可以通过在线解码工具查看一下转换结果
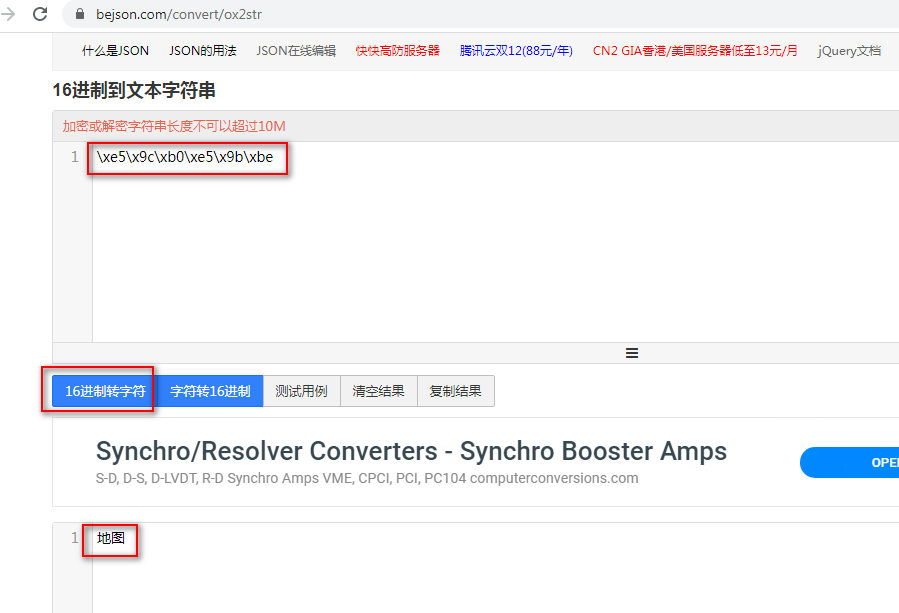 然后说一下,这里为什么不全是字节组成的二进制格式的形式(有人会想不是要求都是bytes型数据么,应该都是010101010这种的或者是像上面是的\xe5\x9c这中的),而是我们有的能正常识别的英语字母和符号?
然后说一下,这里为什么不全是字节组成的二进制格式的形式(有人会想不是要求都是bytes型数据么,应该都是010101010这种的或者是像上面是的\xe5\x9c这中的),而是我们有的能正常识别的英语字母和符号?
这里要说一下python3中默认的字符存储格式,数据存储在文件中和在网络上传输过程中使用的是字节型编码(二进制的形式),在内存中存储的默认是unicode型数据(虽然也是二进制的形式,我们看不到而已),使用print打印时会找到unicode内码表进行转换,转换成对应的字符
比如:“汉”的 Unicode 码点是 0x6c49 转换成utf-8就是0xE6 0xB7 0x89 这两个16进制组成的字节码对应的二进制是不同的,但是他们指代的是同一个字符。因此在你print输出到屏幕上的时候其实你看到的是通过unicode码返找unicode码表对应的字符,而由于所有的字符编码方式都兼容ascii前127个字符编码,unicode也不例外,因此这里英文输出是正常的
二.res.text的返回的是unicode型数据
res.text反馈结果
 当调用res对象的text属性时,会对网络传来的编码数据进行解码res.text会使用默认的解码方式ISO-8859-1进行解码,因为编码不是用的ISO-8859-1因此解码的时候,只有ascii前127个码能找到解码对应的字符,再转换成unicode码,内存中使用,输出屏幕的时候再找到对应的unicode字符,而没有解码对应的就会显示乱码
当调用res对象的text属性时,会对网络传来的编码数据进行解码res.text会使用默认的解码方式ISO-8859-1进行解码,因为编码不是用的ISO-8859-1因此解码的时候,只有ascii前127个码能找到解码对应的字符,再转换成unicode码,内存中使用,输出屏幕的时候再找到对应的unicode字符,而没有解码对应的就会显示乱码
解决此问题可以调用encoding属性并赋值,这里告诉res对象,数据传过来之前使用的是utf-8编码
# req_test1.py
import requests
res = requests.get("[https://www.baidu.com")](https://www.baidu.com))
res.encoding='utf-8'
print(res.text)
查看结果

其实默认情况下,requests对res的text属性返回结果是可以自动完成解码工作的。不过需要在html页面请求头中明确标注以下内容
content=”text/html; charset=UTF-8“
可以把res请求页面换成下面这个带完整请求头的网址试一下,去掉编码说明(必须标注全,只有charset=utf-8没有用,不会自动识别)
# req_test1.py
import requests
res = requests.get("https://www.runoob.com/http/http-content-type.html")
res.encoding='utf-8'
print(res.text)
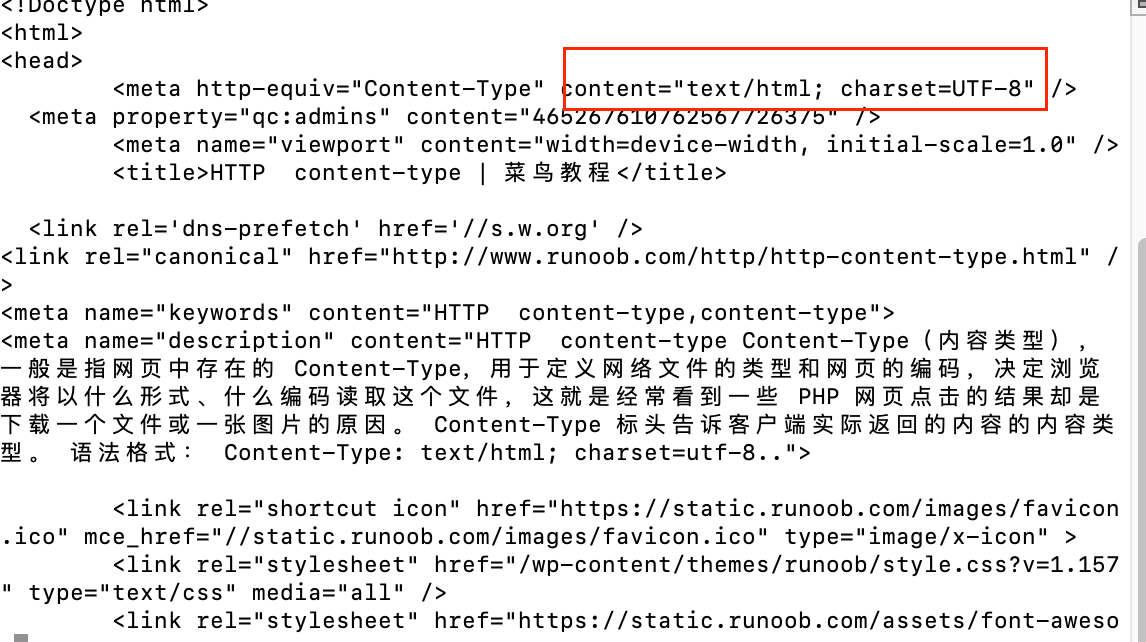 可以看到正式由于html页面中有了那一行,即使没有定义编码类型,也可以看到中文。
可以看到正式由于html页面中有了那一行,即使没有定义编码类型,也可以看到中文。
声明:本博客的原创文章,都是本人平时学习所做的笔记,转载请标注出处,谢谢合作。