 centos7安装和部署kubernetes实践
centos7安装和部署kubernetes实践
k8s环境描述
| 主机名 | ip地址 | 操作系统 | k8s组件版本 |
|---|---|---|---|
| master | 192.168.140.210 | CentOS Linux release 7.4.1708 | v1.20.2 |
| node1 | 192.168.140.211 | CentOS Linux release 7.4.1708 | v1.20.2 |
| node2 | 192.168.140.212 | CentOS Linux release 7.4.1708 | v1.20.2 |
k8s安装和环境配置
以下操作在所有节点同时操作
- 安装docker
# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # yum install docker-ce -y - docker默认下载镜像使用国外镜像源,这里为了能够快速下载镜像,修改成国内镜像源
# tee /etc/docker/daemon.json << eof { "registry-mirrors": [ "http://hub-mirror.c.163.com", "https://docker.mirrors.ustc.edu.cn", "https://registry.docker-cn.com" ] } eof - 启动docker服务,并设置成开机自启动
# systemctl start docker # systemctl enable docker - 关闭selinux
编辑/etc/sysconfig/selinux文件将SELINUX对应的值设置为disabled
当次生效# setenforce 0永久生效
# vim /etc/sysconfig/selinux SELINUX=disabled - 关闭swap
当次生效
# swapoff -a永久生效,编辑/etc/fstab 将下面这行注释掉(即前面填个#),后重启
# /dev/mapper/centos-swap swap swap defaults 0 0 - 关闭firewalld
# systemctl stop firewalld # systemctl disable firewalld - 网络内核参数/etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1永久生效
#sysctl -p - 修改/etc/docker/daemon.json
修改节点cgroup的驱动方式为systemd{ "registry-mirrors": [ "http://hub-mirror.c.163.com", "https://docker.mirrors.ustc.edu.cn", "https://registry.docker-cn.com" ], "exec-opts": ["native.cgroupdriver=systemd"] } - 重启docker服务
# systemctl restart docker # systemctl daemon-reload以上参考官网文档https://docs.docker.com/engine/install/centos/
- 新增k8s源并更新缓存
# tee /etc/yum.repos.d/k8s.repo <<eof [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg eof# yum clean all # yum makecache -y - 修改主机对应的主机名,这里拿master举例,node1和node2需要将master换成node1和node2
# hostnamectl set-hostname master - 修改hosts文件
# cat >> /etc/hosts << eof 192.168.141.200 master 192.168.141.201 node1 192.168.141.202 node2 eof - 安装kubelet、kubectl、kubeadm
# yum install kubelet kubectl kubeadm -y - 启动kubelet服务
# systemctl enable kubelet && systemctl start kubelet
启动服务后使用journalctl -xefu kubelet会看到下面报错信息,这个没关系,因为在kubeadm init前kubelet会一直循环启动,因此会报下面的错误
master kubelet[13437]: F0118 15:18:51.700556 13437 server.go:198] failed to load Kubelet config file /var/lib/kubelet/config.yaml, error failed to read kubelet config file “/var/lib/kubelet/config.yaml”, error: open /var/lib/kubelet/config.yaml: no such file or directory
master节点操作
- kubeadm初始化(control-plane)
# kubeadm init \ --image-repository registry.aliyuncs.com/google_containers \ --kubernetes-version v1.20.2 \ --pod-network-cidr=10.244.0.0/16-
–apiserver-advertise-address(可选) 如果有多个网卡,这里指定一个默认路由走的网卡ip地址,如果就一个网卡,可以省略
-
–image-repository(国内网络环境必选) 推荐这里更改为国内的源,因为国外的很慢
- –kubernetes-version(必选)
这里需要选择你的kubenetes的版本,可以使用下面命令查看一下对应版本
# kubeadm config images list -
–pod-network-cidr(可选) 如果想让集群之后创建的pods之间可以通信,这里需要指定这个参数,并且在kubeadm init后安装网络插件
- –control-plane-endpoint(可选) 当有需求需要对master进行可靠性保障即HA时,需要此参数,后面添加你需要规划的load-balance的地址
-
- kubeadm init初始化成功会出现以下提示 (最好保留此结果,为了方便以后node加入集群使用)
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.140.210:6443 --token jtraq9.sr9ovpi9golptuhh \ --discovery-token-ca-cert-hash sha256:6ad1ec7eb4328f95b393d675dc71d7742b2cda6c96d6baac0efa373c69bd7d85 - (如果kubeadm init过程中报错)请使用下面的命令,重置环境使用下面命令
# kubeadm reset根据kubeadm init成功后提示进行以下几个操作步骤
- 更换KUBECONFIG环境变量(我是root用户,如果你是普通用户,请根据初始化成功提示做相应操作)
# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile # source ~/.bash_profile - 安装网络插件
安装网络插件,默认情况下各个pods之间是不能通信的,因此为了各pod之间能够通信,这里安装flannel插件# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml如果报如下错误
The connection to the server raw.githubusercontent.com was refused - did you specify the right host or port?添加下列行到/etc/hosts,然后重新执行命令即可
199.232.28.133 raw.githubusercontent.com - 查看组件状态
[root@master ~]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused etcd-0 Healthy {"health":"true"}可以看到scheduler和controller-manager状态不正常,这个因为/etc/kubernetes/manifests下的kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0,在文件中注释掉就可以了
kube-controller-manager.yaml 的26行,kube-scheduler.yaml的19行 前面加个#
重启kubelet服务# systemctl restart kubelet再次查看组件状态,恢复正常
[root@master manifests]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"}命令补全法
# source <(kubectl completion bash) - 安装dashboard
k8s提供了一个可图形化管理集群的工具dashboard
下载并安装dashboard# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml使用 kubectl 启动 Dashboard,命令如下:
# kubectl proxykubectl 会使得 Dashboard 可以通过 http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/ 访问,但是需要token,下面生成token
# cat <<EOF | kubectl apply -f - apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard EOF创建一个ClusterRoleBinding
# cat <<EOF | kubectl apply -f - apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard EOF下面命令得到token
# kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template=""得到的token类似
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXY1N253Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIwMzAzMjQzYy00MDQwLTRhNTgtOGE0Ny04NDllZTliYTc5YzEiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.Z2JrQlitASVwWbc-s6deLRFVk5DWD3P_vjUFXsqVSY10pbjFLG4njoZwh8p3tLxnX_VBsr7_6bwxhWSYChp9hwxznemD5x5HLtjb16kI9Z7yFWLtohzkTwuFbqmQaMoget_nYcQBUC5fDmBHRfFvNKePh_vSSb2h_aYXa8GV5AcfPQpY7r461itme1EXHQJqv-SN-zUnguDguCTjD80pFZ_CmnSE1z9QdMHPB8hoB4V68gtswR1VLa6mSYdgPwCHauuOobojALSaMc3RH7MmFUumAgguhqAkX3Omqd3rJbYOMRuMjhANqd08piDC3aIabINX6gP5-Tuuw2svnV6NYQ完成以上操作正常情况下只能在master服务器上打开dashboard,如若想可以远程访问dashboard需要如下操作
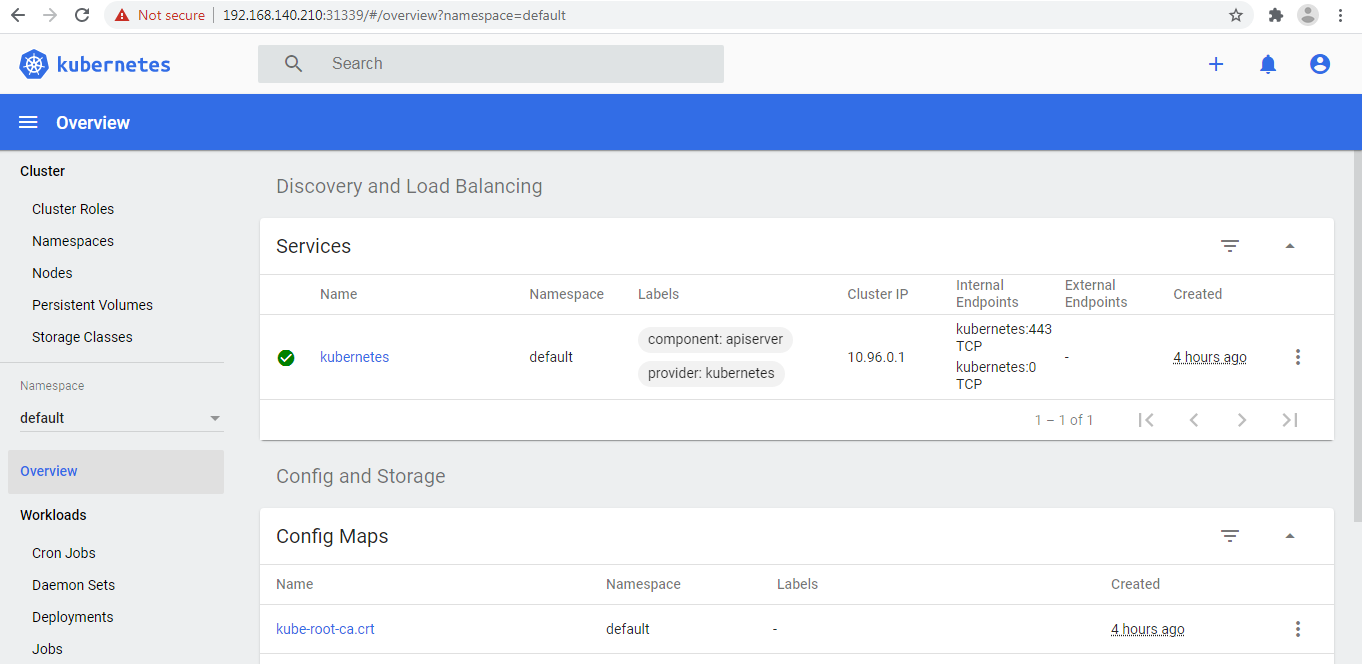
# kubectl -n kubernetes-dashboard edit service kubernetes-dashboard 将type: ClusterIP替换成type: NodePort修改后,查看现在dashboard映射的端口号(我的实验环境为31339)
[root@master ~]# kubectl -n kubernetes-dashboard get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dashboard-metrics-scraper ClusterIP 10.102.147.64 <none> 8000/TCP 110m kubernetes-dashboard NodePort 10.103.154.22 <none> 443:31339/TCP 110m然后打开浏览器访问https://node-ip:31339 输入之前的token即可(nodeip为集群中所有的节点的任意ip即可,192.168.140.210,192.168.140.211,192.168.140.212)
node节点操作
根据kubeadm init返回提示在各个node上如下操作加入k8s集群即可(请按照自己环境的返回结果粘贴)
kubeadm join 192.168.140.210:6443 --token jtraq9.sr9ovpi9golptuhh \
--discovery-token-ca-cert-hash sha256:6ad1ec7eb4328f95b393d675dc71d7742b2cda6c96d6baac0efa373c69bd7d85
在master节点上查看node节点状态,发现node1和node2状态为NotReady ,查找原因
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 4h13m v1.20.2
node1 NotReady <none> 27s v1.20.2
node2 NotReady <none> 6s v1.20.2
查看kubelet日志,发现网络组件没有安装
[root@node1 ~]# journalctl -f -u kubelet
-- Logs begin at 二 2021-01-19 00:51:08 CST. --
1月 19 17:15:37 node1 kubelet[24220]: W0119 17:15:37.190500 24220 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.d
1月 19 17:15:39 node1 kubelet[24220]: E0119 17:15:39.203712 24220 kubelet.go:2163] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
拷贝master节点上的/etc/kubernetes/admin.conf到node1和node2(在master节点上操作)
# scp /etc/kubernetes/admin.conf 192.168.140.211:/etc/kubernetes/
# scp /etc/kubernetes/admin.conf 192.168.140.212:/etc/kubernetes/
添加下列行到/etc/hosts
199.232.28.133 raw.githubusercontent.com
更换KUBECONFIG环境变量
# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
# source ~/.bash_profile
安装网络插件
# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
再次查看node状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 4h27m v1.20.2
node1 Ready <none> 15m v1.20.2
node2 Ready <none> 14m v1.20.2
部署应用
- 启动一个nginx容器,副本数为2
Kubernetes 1.18之后弃用了replicas参数,因此这里选用yml文件部署的方式进行app部署# tee deployment << eof apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 2 # tells deployment to run 2 pods matching the template template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80 eof通过deployment.yml文件创建应用
# kubectl apply -f deployment.yml查看deployment状态
[root@master ~]# kubectl get deployment NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 2/2 2 2 92s查看pods状态
[root@master ~]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-7848d4b86f-2sslj 1/1 Running 0 3m18s 10.244.1.2 node1 <none> <none> nginx-deployment-7848d4b86f-dqxxt 1/1 Running 0 3m18s 10.244.2.4 node2 <none> <none>验证app访问
可以在master,node1,node2这三台机器上通过浏览器访问10.244.1.2和10.244.2.4,看到nginx访问页面,为了方便区分2个app,修改nginx中默认的index.html页面内容[root@node2 ~]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-7848d4b86f-2sslj 1/1 Running 0 24h 10.244.1.2 node1 <none> <none> nginx-deployment-7848d4b86f-dqxxt 1/1 Running 0 24h 10.244.2.4 node2 <none> <none> [root@node1 ~]# kubectl exec -it nginx-deployment-7848d4b86f-2sslj -- bash -c "echo 1.txt > /usr/share/nginx/html/index.html" [root@node2 ~]# kubectl exec -it nginx-deployment-7848d4b86f-dqxxt -- bash -c "echo 2.txt > /usr/share/nginx/html/index.html"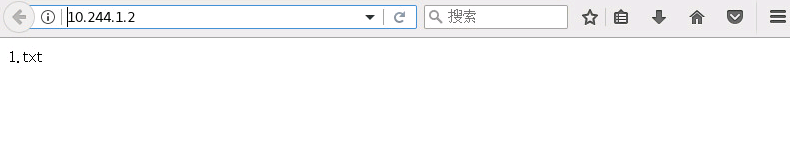

-
service配置
默认情况下,只能在集群的节点上对应用进行访问,但实际环境中,需要将集群中部署的app对外进行映射,可以通过外网进行访问,这是就需要对service进行配置 ,跟之前的dashboard服务一样,这里再熟悉一遍
# tee service_myapp.yml << eof apiVersion: v1 kind: Service metadata: name: my-service spec: selector: app: nginx ports: - nodePort: 10080 protocol: TCP port: 80 targetPort: 80 type: NodePort eof修改可映射端口范围,默认为30000-32767,添加下面字段到/etc/kubernetes/manifests/kube-apiserver.yaml中,找到- –service-cluster-ip-range=10.96.0.0/12,在这个下面填入
--service-node-port-range=1-65535重启kubelet
# systemctl daemon-reload # systemctl restart kubelet创建service
# kubectl apply -f service_myapp.yml然后打开浏览器访问https://node-ip:10080 即可(nodeip为集群中所有的节点的任意ip:(192.168.140.210,192.168.140.211,192.168.140.212)刷新浏览器可以看到交替出现1.txt和2.txt内容
声明:本博客的原创文章,都是本人平时学习所做的笔记,转载请标注出处,谢谢合作。