 使用helm安装prometheus实践
使用helm安装prometheus实践
| 主机名/功能 | ip地址/访问方式 | 操作系统 | 版本 | 备注 |
|---|---|---|---|---|
| master | 192.168.140.210 | CentOS Linux release 7.4.1708 | v1.20.2 | 物理机 |
| node1 | 192.168.140.211 | CentOS Linux release 7.4.1708 | v1.20.2 | 物理机 |
| node2 | 192.168.140.212 | CentOS Linux release 7.4.1708 | v1.20.2 | 物理机 |
| node3 | 192.168.140.213 | CentOS Linux release 7.4.1708 | v1.20.2 | 物理机 |
实验目的
完善k8s实验环境,通过helm方便快速的搭建prometheus项目监控k8s实验环境,了解prometheus的工作原理
前提条件
已完成kubernetes的环境搭建和helm的客户端安装
项目地址
https://github.com/prometheus-operator/kube-prometheus
项目包含的组件有以下几个
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
安装流程
使用helm chart安装prometheus项目
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus-project prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
输出如下提示,安装成功
NAME: prometheus-project LAST DEPLOYED: Thu Apr 15 16:39:08 2021 NAMESPACE: monitoring STATUS: deployed REVISION: 1 NOTES: kube-prometheus-stack has been installed. Check its status by running: kubectl –namespace monitoring get pods -l “release=prometheus-project”
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
查看都安装了哪些pod
[root@master ~]# kubectl get pod -n monitoring -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-prometheus-project-kube-pr-alertmanager-0 2/2 Running 0 16h 10.244.2.65 node2 <none> <none>
prometheus-project-grafana-7dc4d8444-9sx7f 2/2 Running 0 16h 10.244.1.63 node1 <none> <none>
prometheus-project-kube-pr-operator-766b5f96b7-4gn6x 1/1 Running 0 16h 10.244.1.62 node1 <none> <none>
prometheus-project-kube-state-metrics-5664f9bbf9-96vcl 0/1 ImagePullBackOff 0 16h 10.244.3.60 node3 <none> <none>
prometheus-project-prometheus-node-exporter-2ztqx 1/1 Running 0 16h 192.168.140.212 node2 <none> <none>
prometheus-project-prometheus-node-exporter-cfbtf 1/1 Running 0 16h 192.168.140.210 master <none> <none>
prometheus-project-prometheus-node-exporter-kfvnk 1/1 Running 0 16h 192.168.140.211 node1 <none> <none>
prometheus-project-prometheus-node-exporter-nwk2x 1/1 Running 0 16h 192.168.140.213 node3 <none> <none>
prometheus-prometheus-project-kube-pr-prometheus-0 2/2 Running 0 16h 10.244.3.61 node3 <none>
可以看到上面有一步status显示ImagePullBackOff,查找具体原因
# kubectl describe pod prometheus-project-kube-state-metrics-5664f9bbf9-96vcl -n monitoring
Events: Type Reason Age From Message —- —— —- —- ——- Warning Failed 33m (x3901 over 17h) kubelet Error: ImagePullBackOff Normal BackOff 3m43s (x4026 over 17h) kubelet Back-off pulling image “k8s.gcr.io/kube-state-metrics/kube-state-metrics:v1.9.8”
原因是k8s.gcr.io国内访问不了,替换成quay.io即可
# kubectl edit pod prometheus-project-kube-state-metrics-5664f9bbf9-96vcl -n monitoring
将image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v1.9.8替换成image: quay.io/coreos/kube-state-metrics:v1.9.8
等待一段时间后恢复正常,再次查看
[root@master ~]# kubectl get pod -n monitoring -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES alertmanager-prometheus-project-kube-pr-alertmanager-0 2/2 Running 0 18h 10.244.2.65 node2
prometheus-project-grafana-7dc4d8444-9sx7f 2/2 Running 0 18h 10.244.1.63 node1 prometheus-project-kube-pr-operator-766b5f96b7-4gn6x 1/1 Running 0 18h 10.244.1.62 node1 prometheus-project-kube-state-metrics-5664f9bbf9-96vcl 1/1 Running 0 18h 10.244.3.60 node3 prometheus-project-prometheus-node-exporter-2ztqx 1/1 Running 0 18h 192.168.140.212 node2 prometheus-project-prometheus-node-exporter-cfbtf 1/1 Running 0 18h 192.168.140.210 master prometheus-project-prometheus-node-exporter-kfvnk 1/1 Running 0 18h 192.168.140.211 node1 prometheus-project-prometheus-node-exporter-nwk2x 1/1 Running 0 18h 192.168.140.213 node3 prometheus-prometheus-project-kube-pr-prometheus-0 2/2 Running 0 18h 10.244.3.61 node3
查看下monitoring下service都有哪些,类型和端口号
[root@master ~]# kubectl get svc -n monitoring
monitoring alertmanager-operated ClusterIP None
9093/TCP,9094/TCP,9094/UDP 21h monitoring prometheus-operated ClusterIP None 9090/TCP 21h monitoring prometheus-project-grafana ClusterIP 10.111.37.13 80/TCP 21h monitoring prometheus-project-kube-pr-alertmanager ClusterIP 10.99.21.4 9093/TCP 21h monitoring prometheus-project-kube-pr-operator ClusterIP 10.110.109.186 443/TCP 21h monitoring prometheus-project-kube-pr-prometheus ClusterIP 10.97.255.154 9090/TCP 21h monitoring prometheus-project-kube-state-metrics ClusterIP 10.110.99.116 8080/TCP 21h monitoring prometheus-project-prometheus-node-exporter ClusterIP 10.96.136.130 9100/TCP 21h
默认service对应的都是ClusterIp,这种类型的service是不能够对外提供服务的,因此这里将service服务类型转换成NodePort,即可以通过访问nodeip+port的方式访问上面的服务
这里为了方便以后调试将prometheus-project-grafana、prometheus-project-kube-pr-alertmanager、prometheus-project-kube-pr-prometheus 对应的类型都改成为NodePort
# kubectl edit svc prometheus-project-grafana -n monitoring
# kubectl edit svc prometheus-project-kube-pr-alertmanager -n monitoring
# kubectl edit svc prometheus-project-kube-pr-prometheus -n monitoring
type: ClusterIp换成type: NodePort
[root@master ~]# kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-operated ClusterIP None
9093/TCP,9094/TCP,9094/UDP 22h prometheus-operated ClusterIP None 9090/TCP 22h prometheus-project-grafana NodePort 10.111.37.13 80:319/TCP 22h prometheus-project-kube-pr-alertmanager NodePort 10.99.21.4 9093:51955/TCP 22h prometheus-project-kube-pr-operator ClusterIP 10.110.109.186 443/TCP 22h prometheus-project-kube-pr-prometheus NodePort 10.97.255.154 9090:25125/TCP 22h prometheus-project-kube-state-metrics ClusterIP 10.110.99.116 8080/TCP 22h prometheus-project-prometheus-node-exporter ClusterIP 10.96.136.130 9100/TCP 22h
prometheus自带web端
alertmanager自带web端
grafana官网提示默认用户和密码都是admin,但是这里实验并不是这个,要想得到密码需要以下步骤
kubectl get secret -n monitoring prometheus-project-grafana -o yaml
找到下面字段
data: admin-password: cHJvbS1vcGVyYXRvcg== admin-user: YWRtaW4=
其中admin-password对应就是密码,admin-user对应的就是用户名,不过用了base64做了编码,下面进行解码
[root@master ~]# echo "cHJvbS1vcGVyYXRvcg==" | base64 --decode
prom-operator
登录grafana
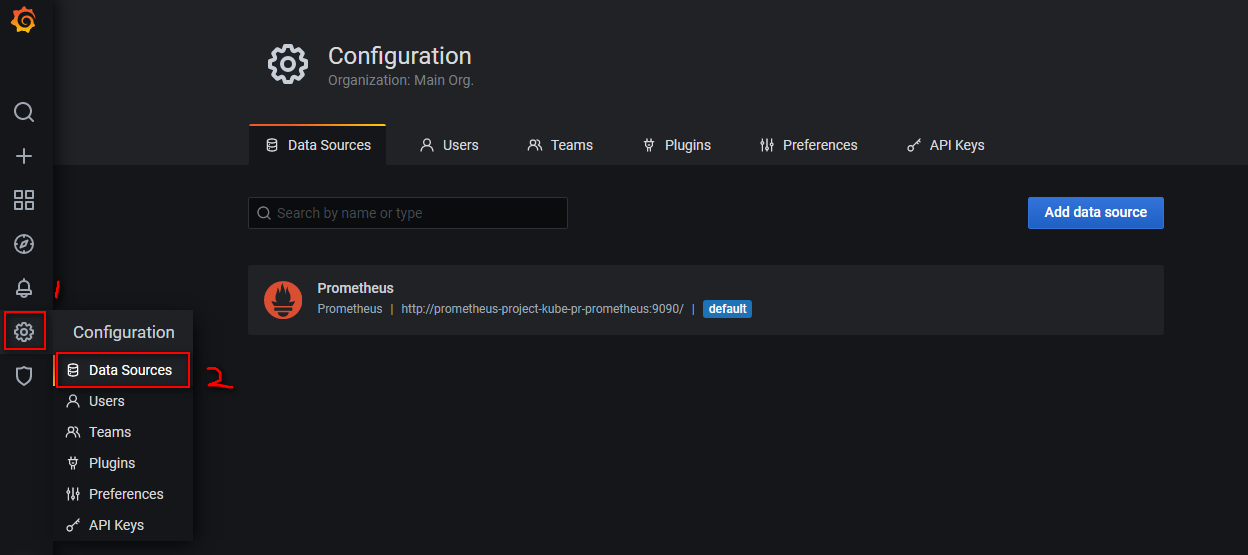
查看数据源时可以看到默认已经做好了集成
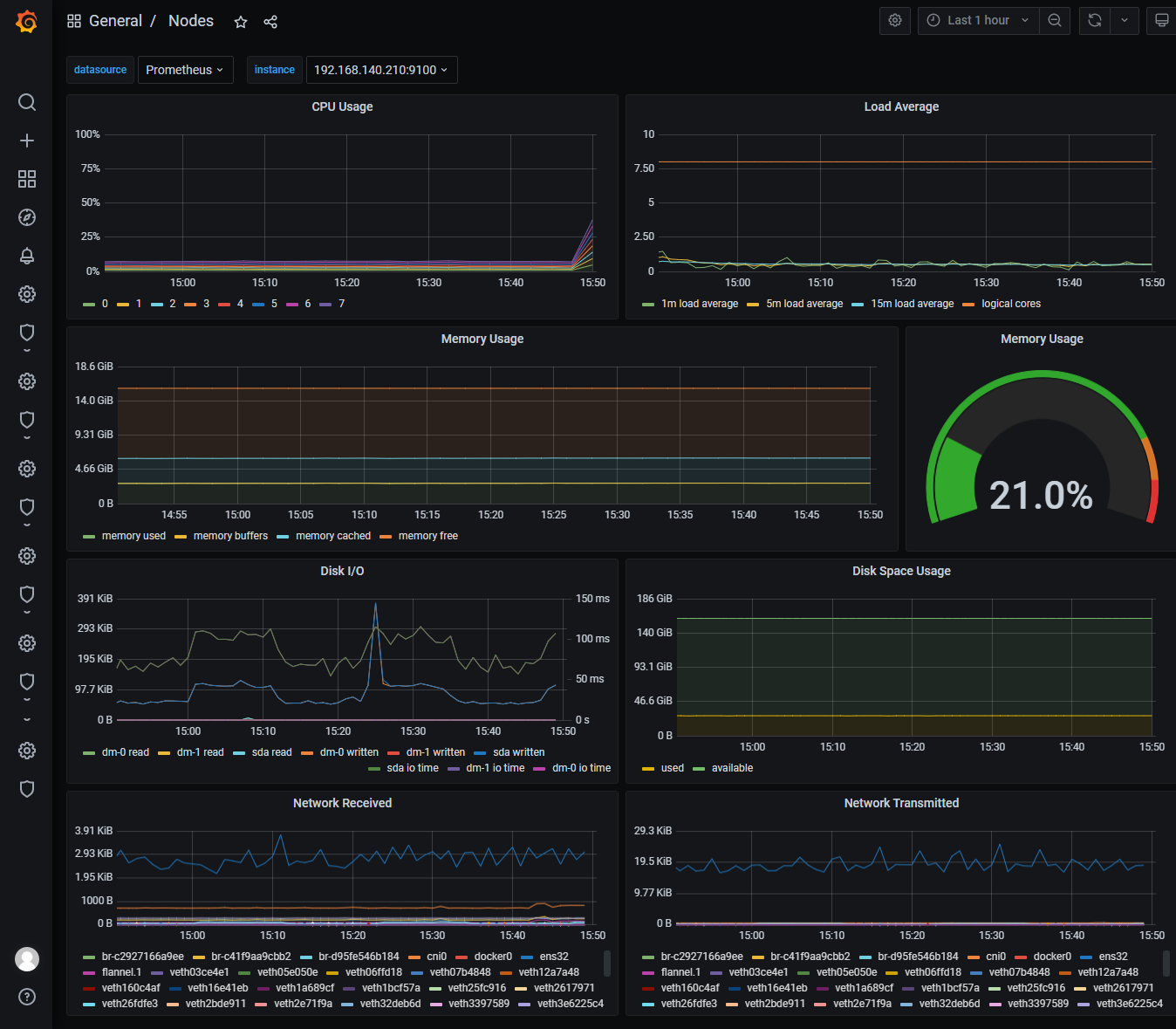
可以看到有各种已经定义好的dashboard选择
由于比较多只选择几个进行展示
成果展示
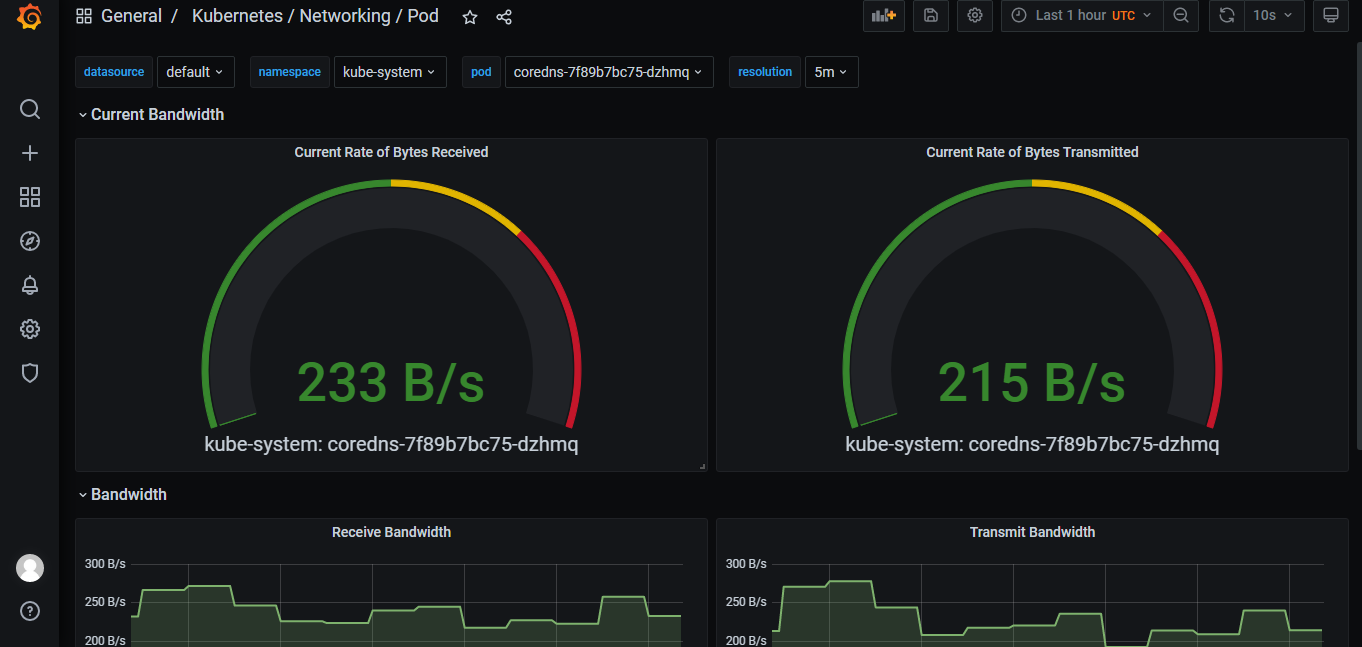
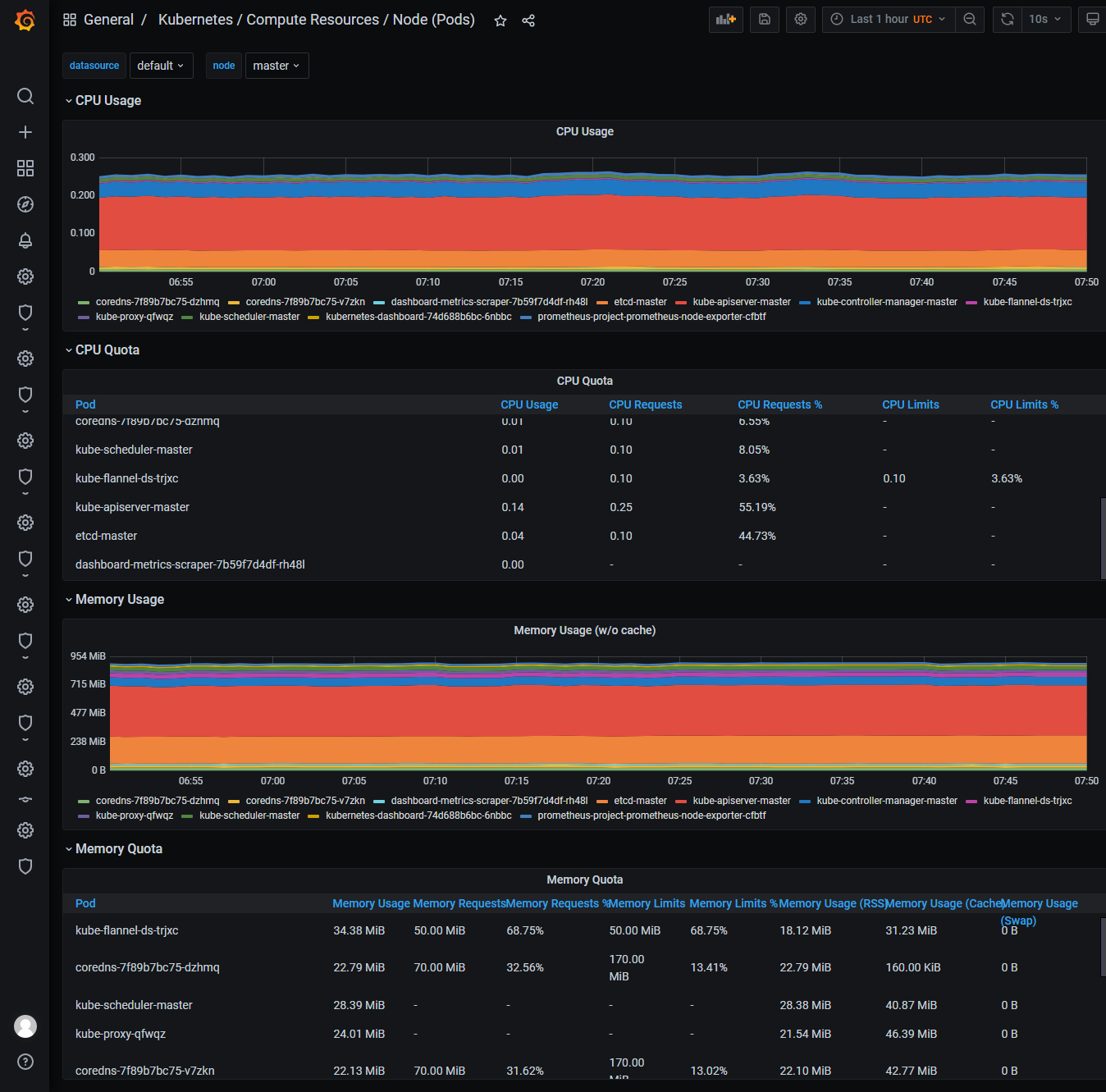
声明:本博客的原创文章,都是本人平时学习所做的笔记,转载请标注出处,谢谢合作。